With so much data being generated daily, there are many opportunities for developing a better understanding of the world around us. Yet, to turn this data into actionable information, we need robust models that represent complexity in the data being studied.
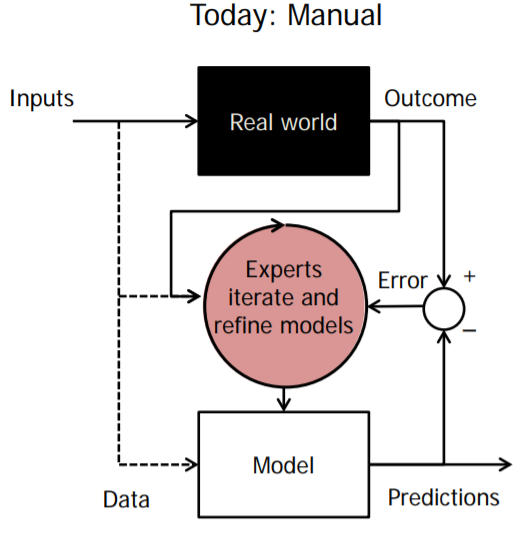
Most work on developing such models today is done manually: Subject matter experts with insights into the inner workings of the system are linked with data scientists who possess the tools to develop these models. But today, with advances in the availability of computational resources and machine learning methodology, there is an opportunity to change this by removing the human-in-the-loop element from one of these steps. Automating the model development process can make it much easier to harness the power of the data that is becoming available through open sources and improved sensing, while also not being limited by the availability of Data Scientists.
The DARPA Data-Driven Discovery of Models (D3M) program aims to automate the model discovery process. The vision of the program is that any subject matter expert with no data science background should be able to create empirical models using the tools available in the D3M repository.
 |
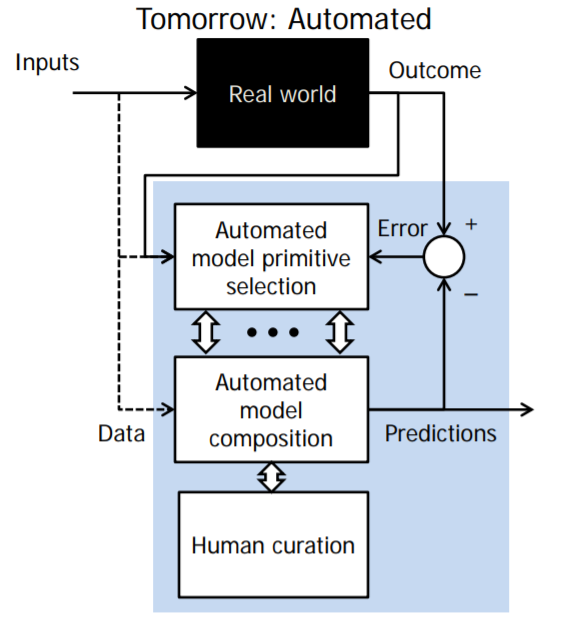 |
The PLAI group has been working in the context of the D3M project, contributing several core primitives and developing open source versions of its research for automated use by subject matter experts. Our major contribution to D3M is Hasty: A Generative Model Compiler. We have also helped implement multiple machine learning techniques as part of this program, and performed theoretical studies in Automated Machine Learning.
To demonstrate the power of AutoML, we have developed Black Box ML, a system which allows automated tabular classification system.
Contributors
PI: Frank Wood (UBC)
Co-PIs: Kevin Layton Brown (UBC) – Katrina Ligget (Hebrew University of Jerusalem)
Most members of the PLAI group contribute to this project.