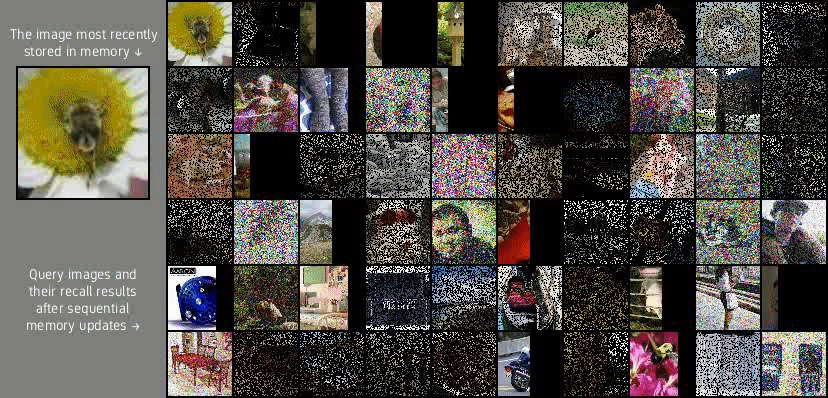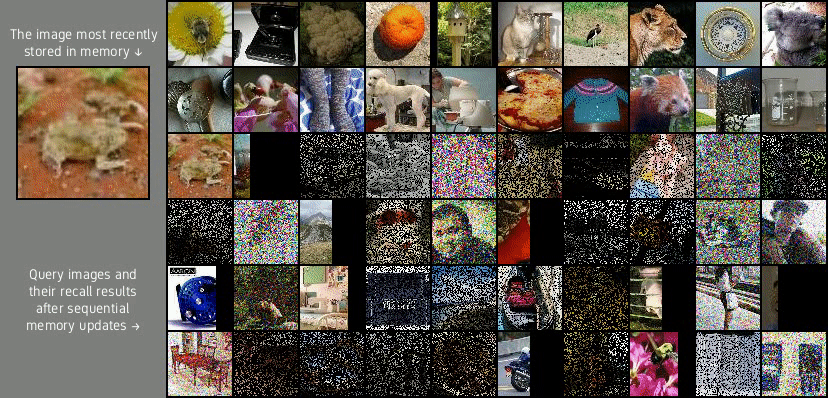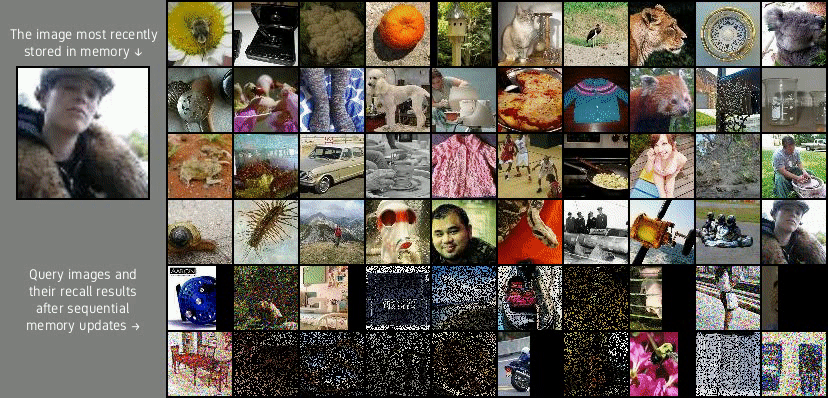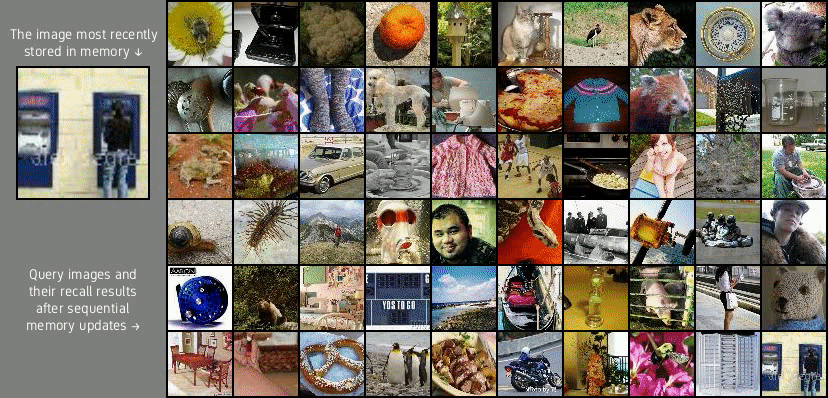PLAI group member Jason Yoo and colleagues, under the supervision of Dr. Frank Wood and Dr. Geoff Pleiss, have released a new paper on training autoregressive video diffusion models from a continuous video stream that outputs one video frame at a time. The AI community has long sought models and algorithms that learn in a fundamentally human way; from birth to death, learning as we live. Our paper demonstrates that learning video diffusion models in such a way is not only possible but remarkably can also be competitive with standard offline training approaches given the same number of gradient steps. In addition, our paper introduces three new lifelong video generative modeling datasets generated from synthetic environments of increasing complexity: Lifelong Bouncing Balls, Lifelong 3D Maze, and Lifelong PLAICraft.

How Are the Models Lifelong Learned?
In standard offline learning, video diffusion models typically train on independently and identically distributed (i.i.d.) sampled video frames from a large dataset of loosely related videos. In our lifelong learning setup, video diffusion models are trained online on a video stream that sequentially iterates through a single, very long video. At each training iteration, the video diffusion models observe one new video frame and take one gradient step.
The models’ task is to predict the future video frames conditioned on the preceding video frames. Our lifelong learning setup trains the models using a sliding window scheme. At training step t, the model conditions on a fixed number of most recent video frames from the video stream and learns to denoise the subsequent video frames. At training step t+1, the model’s context window slides by one video frame and the same procedure repeats indefinitely. This process is illustrated in the figure below.

Unsurprisingly, performing SGD on the minibatch solely comprised of the current timestep sliding window video frames leads to suboptimal performance. Therefore, we augment the minibatch with past timestep sliding window video frames that are saved in the replay buffer—a technique commonly known as experience replay. While our paper’s lifelong learning results are based on experience replay, we note that this training setup is compatible with other lifelong learning algorithms.
Datasets and Model Samples
As no prior work has attempted to lifelong learn video models on a continuous video stream, we introduce and experiment with three new video lifelong learning datasets: Lifelong Bouncing Balls, Lifelong 3D Maze, and Lifelong PLAICraft. Each dataset contains over a million video frames derived from a single video and is designed to test how data stream characteristics such as perceptual complexity, frame repetitiveness, rare events, and nonstationarity affect lifelong learning. Our video datasets present novel opportunities to learn video models in learning regimes one step closer to that of biological agents. We now briefly elaborate on each dataset and showcase the lifelong learned video diffusion model samples.
Lifelong Bouncing Balls


(middle and bottom rows) for the Lifelong Bouncing Balls datasets. Given the 10 initial video frames marked by red borders,
the model produces the next 40 frames.
Lifelong Bouncing Balls is the simplest of the three datasets. It contains 1 million 32×32 RGB video frames that depict two colored balls that deterministically bounce around and change colors for 28 hours. There are two versions of the dataset where the ball colors do and do not irreversibly change throughout the video stream to assess the effect of frame detail repetitiveness on video lifelong learning. These two versions are depicted in the left and right subfigures of Figure 2. Video diffusion models lifelong learned with experience replay generate videos with realistic ball motion and color transitions.
Lifelong 3D Maze

(middle and bottom rows) for the Lifelong 3D Maze dataset. Given the 10 initial video frames marked by red borders,
the model produces the next 40 frames.
Lifelong 3D Maze contains 1 million 64×64 RGB video frames that depict a first-person view of an agent that navigates a 3D maze for 14 hours (if the maze feels familiar to you, it is because the maze was one of the Windows 95 screensavers). The maze is randomly generated and contains various sparsely occurring objects such as polyhedral rocks that flip the agent and smiley faces that regenerate the maze. Video diffusion models lifelong learned with experience replay generate realistic maze traversal footages that correctly handle rare events.
Lifelong PLAICraft

(middle and bottom rows) for the Lifelong PLAICraft dataset. Given the 10 initial video frames marked by red borders,
the model produces the next 20 frames.
Lifelong PLAICraft is the most complex of the three datasets. It contains 1.85 million 1280×768 RGB video frames that depict a first-person view of an anonymous player who plays multiplayer Minecraft survival world for 54 hours. The video stream captures continuous play sessions from the PLAICraft project and contains clips featuring various biomes, mining, crafting activities, construction, mob fighting, and player-to-player interactions. Thus, the video stream is highly nonstationary and its characteristics change over time in multiple timescales (ex. day-night cycle vs the player sporadically visiting their home). Video diffusion models lifelong learned with experience replay on the Stable Diffusion-encoded video frames successfully capture perceptual details of the Minecraft video frames, in particular details associated with objects present in every gameplay frame (ex. player name, item bar, equipped item). Interestingly, the model also captures player-like behaviors such as spontaneously opening the user inventory (Figure 1 bottom row, leftmost column) and the in-game chat interface (Figure 4 middle row, rightmost column).
Final Remarks
We are genuinely excited for the future of video model lifelong learning. Our findings show that moderate-sized video diffusion models, lifelong learned on just two days’ worth of video frames, can generate short and plausible videos of challenging environments like Minecraft. Looking ahead, we hypothesize that large video diffusion models lifelong learned on years’ worth of video frames could unlock the ability to generate long and temporally coherent videos of highly complex environments. As video modeling is a key component of many world models such as GameNGen and Oasis, these advancements could pave the way for new life-like approaches to learning, planning, and control in embodied AI agents. We are eager to see where this journey leads and invite you to check out our full paper for additional details and analysis. Thank you for reading!